































































































































































































































Nat. Chem. Biol. | 上海药物所发布PBCNet2.0,加速探针发现和先导化合物优化
2026年6月12日,《自然-化学生物学》(Nature Chemical Biology)在线发表了中国科学院上海药物研究所郑明月研究员、张素林研究员和王明亮研究员团队合作完成的题为“Atomic-Level Protein-Ligand Recognition with PBCNet2.0 for Probe Discovery“的研究论文。该研究提出蛋白质-配体相对结合亲和力预测深度学习模型PBCNet2.0,在多个公开基准测试集上,其预测精度达到工业界高精度方法Schrödinger FEP+的水平,为先导化合物优化和小分子探针发现提供了兼具精度、效率与可解释性的智能计算工具。
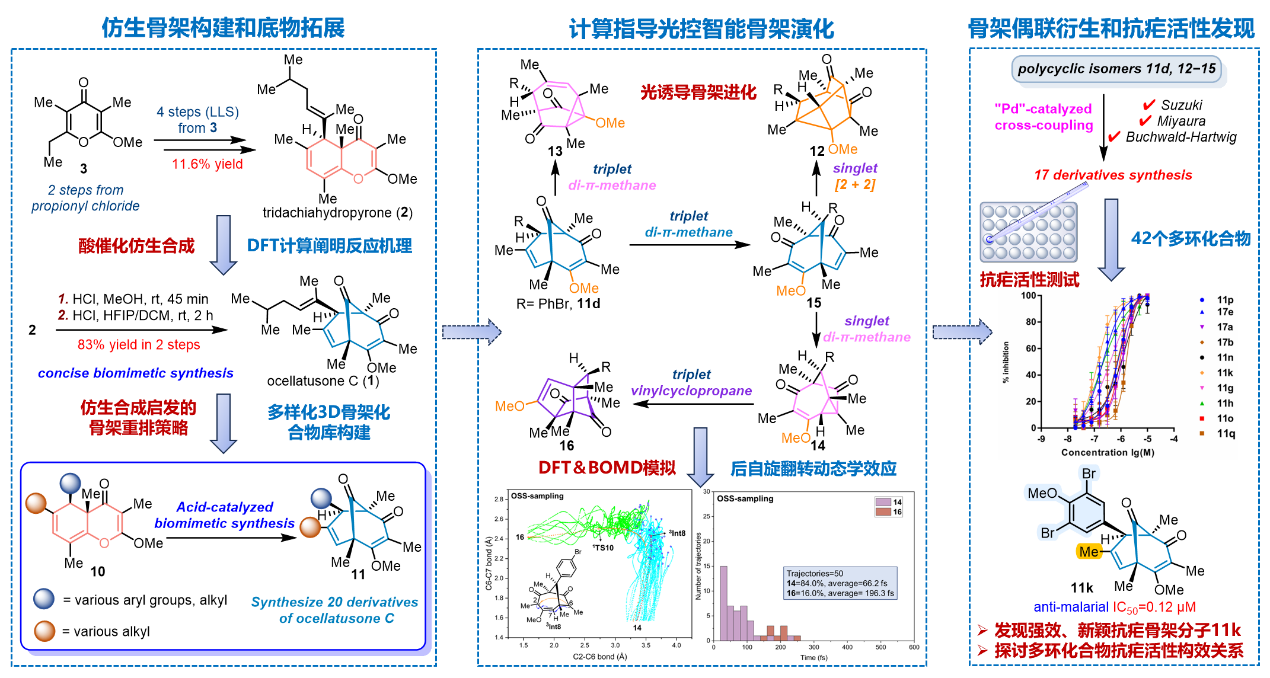
在新药研发中,先导化合物优化是连接早期发现与临床前开发的关键环节。药物化学家需要在有限时间内围绕初始活性分子设计、合成并测试系列化合物,同时优化结合亲和力、选择性及ADME/T等关键性质。由于化学空间组合庞大,传统“设计-合成-测试-分析”(DMTA)循环往往依赖专家经验和反复试错,周期长,成本高。对接打分、MM-GB/SA、自由能微扰(FEP)等计算方法虽已广泛应用,但仍存在计算开销大、对专家设置依赖强、对结构变化敏感等局限性。近年来,深度学习为亲和力预测带来新机遇,但在系列化合物相对排序、结果可解释性和前瞻性实验验证方面仍难满足真实项目需求。针对这些挑战,PBCNet2.0面向先导化合物优化和探针开发场景,建立兼具预测精度、计算效率和可解释性的相对结合亲和力预测模型。
PBCNet2.0的核心突破在于利用基于笛卡尔张量的等变神经网络,直接从蛋白质-配体复合物三维结构中学习原子级相互作用,捕捉距离、方向、角度等精细几何信息,并据此预测两个候选分子的结合亲和力差异。研究团队基于BindingDB构建大规模训练数据,覆盖约28万个小分子和1100余个蛋白靶点共860万复合物结构,为模型学习跨靶点、跨化学系列的相互作用规律提供了基础。
基准测试显示,PBCNet2.0的预测性能达到Schrödinger FEP+水平;在引入少量项目数据进行微调后,模型性能进一步提升,并持续优于Schrödinger FEP+。
研究还表明,PBCNet2.0并非简单记忆分子结构,而是能够识别决定结合强度的关键蛋白质-配体相互作用,因此预测结果具有较好的可解释性。基于这种原子级相互作用识别能力,PBCNet2.0在蛋白质突变预测任务中展现出涌现能力:即使训练阶段未接触突变样本,模型仍能预测部分靶点突变对药物结合选择性的影响,并解释多个临床相关突变导致抑制剂选择性变化的分子作用机制。
研究团队进一步在ENPP1和ALDH1B1两个靶标上开展前瞻性湿实验验证。结果显示,PBCNet2.0能有效指导单原子替换、对映体选择和关键结合残基识别等真实药物优化与探针发现任务,展示了其在实验驱动分子优化中的应用潜力。
上海药物所、临港实验室和上海科技大学联合培养博士生虞杰,上海药物所博士生盛夏、范哲欢,上海药物所硕士生王照坤和同济大学研究员曹端华为论文共同第一作者。上海药物所郑明月研究员、张素林研究员和王明亮研究员为本文共同通讯作者。该研究得到了中国科学院战略性先导科技专项、国家自然科学基金、国家重点研发计划、临港实验室、中国科学院青年创新促进会和中国科协青年人才托举工程等项目支持,同时得到上海国家蛋白质科学中心、上海高等研究院及中国科学院大型蛋白质制备系统工作人员在数据收集与分析中提供的技术支持。
全文链接:https://www.nature.com/articles/s41589-026-02241-x
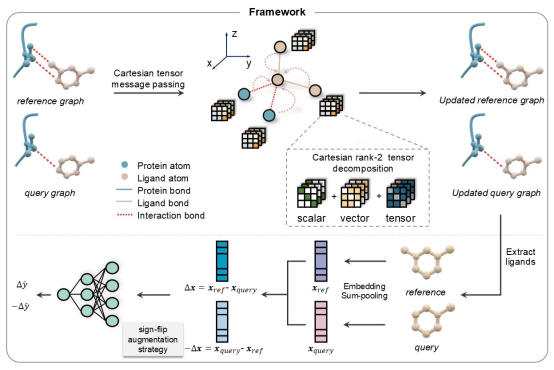
PBCNet2.0模型架构
(供稿部门:郑明月课题组;供稿人:虞杰;审核:刁文桐;责编:宋文珂)